03-05 6085人
Umi-OCR 文字识别工具
免费、开源、可批量的离线OCR软件;适用于 Windows10,11 平台。
- 免费:本项目所有代码开源,完全免费。
- 方便:解压即用,离线运行,无需网络。
- 批量:可批量导入处理图片,结果保存到本地 txt / md / jsonl 多种格式文件。也可以即时截屏识别。
- 高效:采用 PaddleOCR-json C++ 识别引擎。只要电脑性能足够,通常比在线OCR服务更快。
-
精准:默认使用PPOCR-v3模型库。除了能准确辨认常规文字,对手写、方向不正、杂乱背景等情景也有不错的识别率。可设置忽略区域排除水印、设置文块后处理合并排版段落,得到规整的文本。
下载
Umi-OCR 软件本体含 简体中文&英文 通用识别库。
配套 多国语言识别扩展包 可导入繁中,英,日,韩,俄,德,法识别库,请按需下载。
Github下载:https://github.com/hiroi-sora/Umi-OCR/releases
蓝奏云下载:https://hiroi-sora.lanzoul.com/s/umi-ocr
兼容性
- 系统支持 Win10 x64 及以上版本。
- CPU必须具有AVX指令集。常见的家用CPU一般都满足该条件。(出现初始化引擎失败等问题时请检查CPU是否兼容,见楼下置顶回复)
简单上手
准备
下载压缩包并解压全部文件即可。
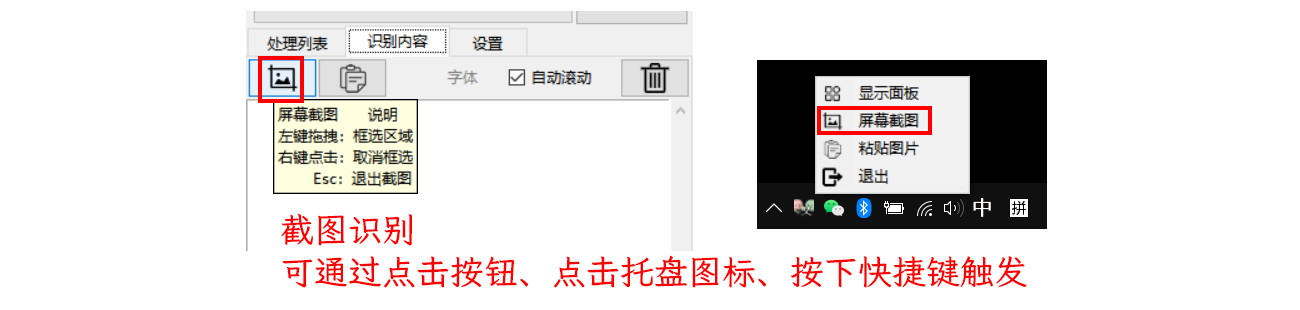
截图识别
点击截图按钮或自定义快捷键,唤起截图识别。
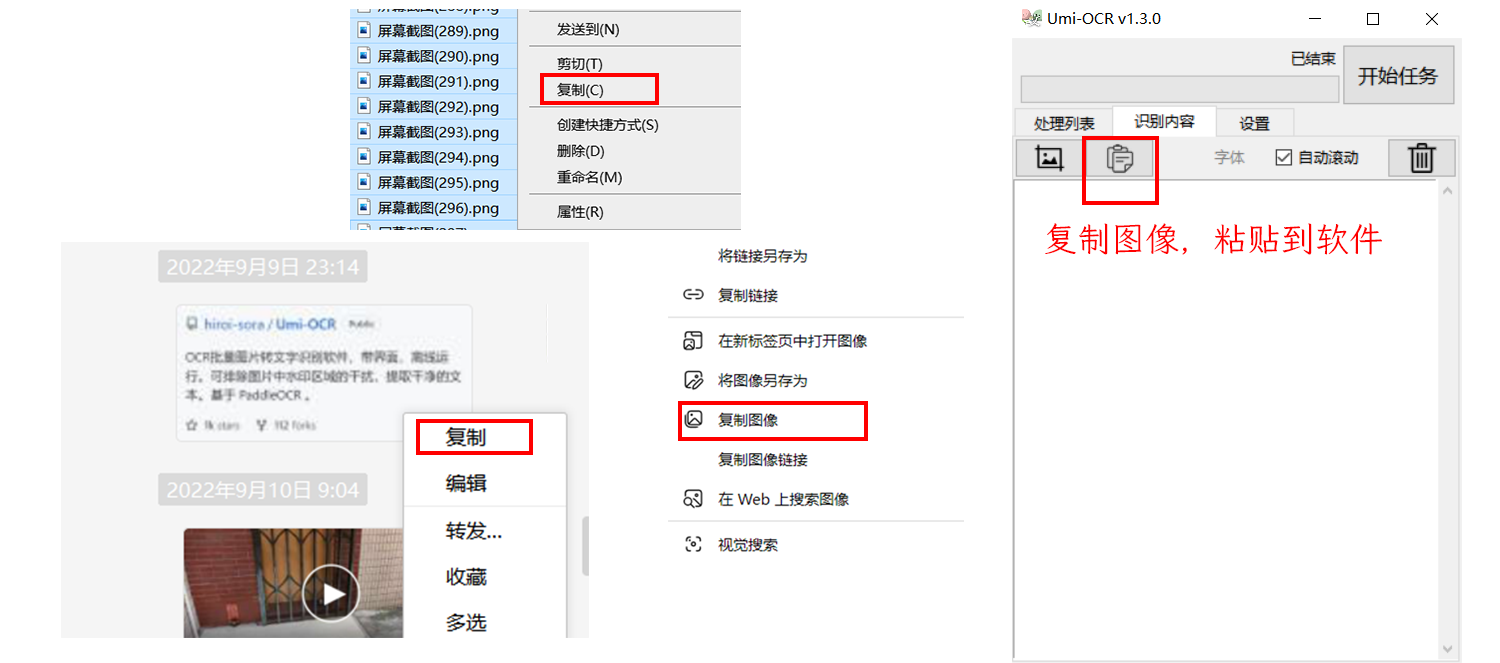
粘贴图片到软件
在任何地方(如文件管理器,网页,微信)复制图片,软件上点击粘贴按钮,自动识别。
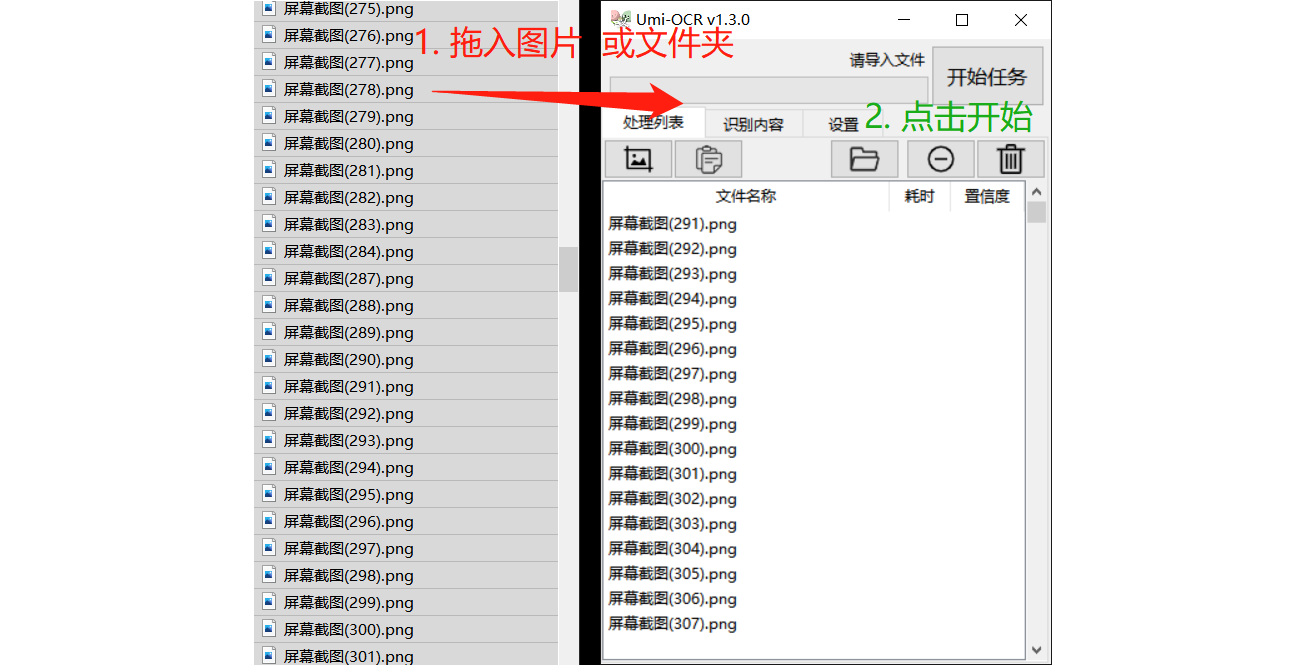
批量识别本地图片文件
将图片或文件夹拖进软件,批量转换文字。也可以点击按钮打开浏览窗口导入。
文本块后处理功能
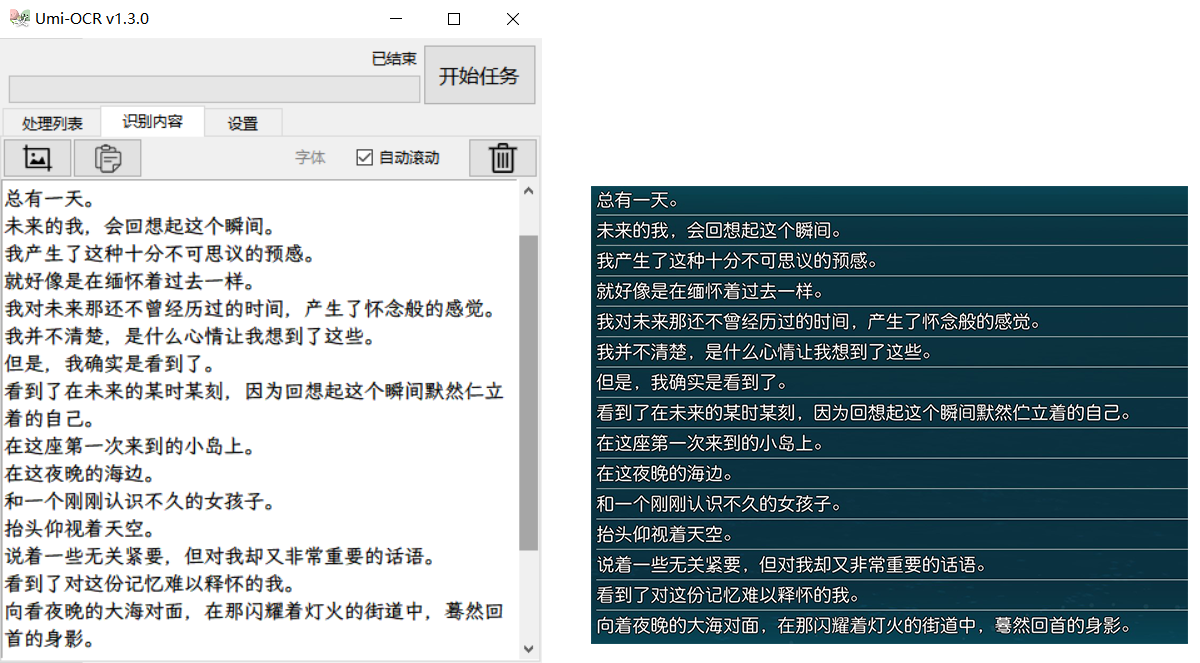
OCR识别出的文本是按“块”划分的,通常一行文字分为一块,有时还会将一行误划分为多块,这给阅读带来了不便。文本块后处理就是对文本块进行再加工的过程,合并同一行或同一段落内的文字,按正确的顺序排序。
下图表示不同排版应该选用何种处理方案:

忽略区域功能
忽略区域是本软件特色功能,可用于排除图片中水印的干扰,让识别结果只留下所需的文本。
通过设置页的 忽略区域编辑器 进入配置。
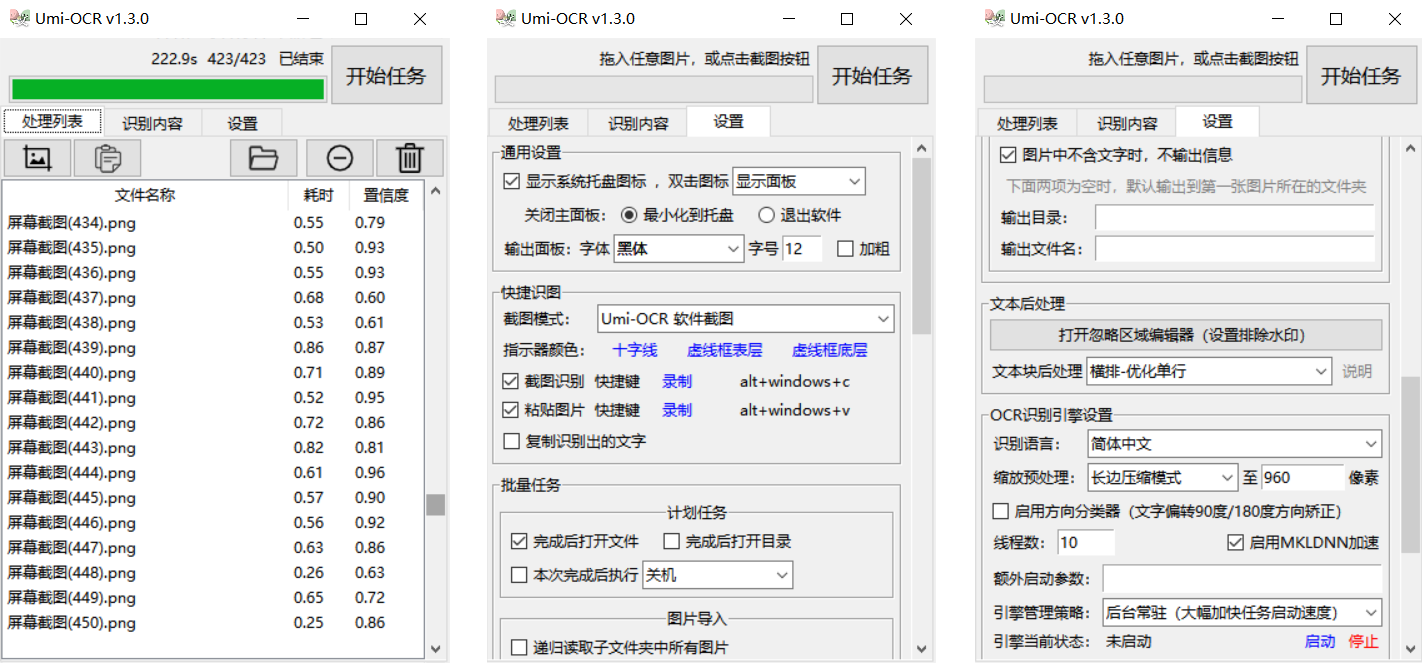
其他设置项
软件内有详尽的提示,鼠标悬停在设置项UI上即可显示提示框。
更多高级功能说明,请见项目Github页面。
更新日志
v1.3.1 2022.11.4
- 修Bug:快捷键模块重写,引入pynput库,舍弃keyboard库,解决几率失效、录制不正确等Bug。
- 新功能:添加开机自启,桌面快捷方式,开始菜单快捷方式。
- 新功能:多开软件时提示。
- 新功能:截图时隐藏窗口。
- 调整UI:使用频率极低的设置项设为隐藏的高级选项。
- 优化:检查引擎组件是否存在。
-
优化:
横排-合并多行-自然段优化逻辑,支持0~2全角空格首行缩进。
v1.3.0 2022.9.29
- 框选截屏
- 系统托盘图标
- 引擎进程常驻
- 文本块后处理模块
- 重制UI
- 自定义主输出栏字体
-
更新PaddleOCR-json模块至
v1.2.1,提供剪贴板支持。 - 修正了Bug:系统语言兼容性问题。
- 修正了Bug:微信图片粘贴问题。
v1.2.6 2022.9.1
-
更新PaddleOCR-json模块至
v1.2.0,提高识别速度、准确度。 - 调整UI:更方便地用下拉框切换识别语言。
- 调整UI:可以从主窗口任意位置/任意选项卡拖入图片。
- 修正了Bug:提高程序健壮性,增加启动子进程时的更多异常处理情况。
- 修正了Bug:彻底解决了对边缘过窄的图片,识别结果不准确的问题。
- 优化适配PP-OCRv3模型,彻底解决了v3版模型比v2慢、不准的问题。
…………
欢迎留言